domingo, 2 de agosto de 2015
Distribución de Probabilidades Discretas y Continuas
Distribución de Probabilidades Discretas y Continuas
DISTRIBUCIONES DISCRETAS
En R es posible calcular valores relacionados con las distribuciones de probabilidad de las principales variables aleatorias discretas. Los nombres reservados a algunas de esas distribuciones son:
• Binomial: binom
• Hipergeométrica: hyper
• Poisson: pois
• Binomial negativa: nbinom
• Geométrica: geom.
Los nombres anteriores, sin embargo, no son sentencias de R que produzcan una salida válida. Es necesario anteponerles los prefijos "d" para la función de masa o función de probabilidad, "p" para la función de distribución acumulada, "r" para generar valores aleatorios y "q" para la función cuantil (inversa de la función de distribución). A continuación vemos algunos ejemplos.
- Calcular la probabilidad de que una variable aleatoria binomial de parámetros n=10, p=0.3 tome el valor 4:
> dbinom(4,size=10,prob=0.3)
[1] 0.2001209
> dbinom(4,10,0.3)
[1] 0.2001209
- Probabilidad acumulada en el valor 5 (se incluye la probabilidad de este valor) de una variable aleatoria de Poisson de parámetro l=2:
> ppois(5,2)
[1] 0.9834364
- Generar 10 valores aleatorios de una distribución de Poisson de parámetro 3,52:
> rpois(10,3.52)
[1] 4 3 3 3 4 5 4 1 2 1
Es de hacer notar que cada vez que se ejecuta la sentencia anterior salen, evidentemente, valores diferentes.
- Calcular la probabilidad de conseguir 4 ases al extraer 4 cartas de una baraja (se supone que hay 8 ases). Aquí la variable aleatoria que representa el número de ases entre las 4 cartas elegidas es una variable aleatoria hipergeométrica de parámetros:
N=40; n=4; p(probabilidad inicial de éxito)=0.2
Esta distribución hipergeométrica se expresa en algunos casos como H(40,4,0.2). En otros, como es el caso de R, se pone en la forma H(8,32,4), siendo 8 el número de "bolas blancas", 32 el número de "bolas negras" y 4 el número de extracciones, y éxito equivale a "bola blanca". Por tanto, para calcular P(X=4) hacemos:
> dhyper(4,8,32,4)
[1] 0.0007659481
Este valor se podría haber obtenido de forma alternativa mediante la fórmula de la distribución hipergeométrica:
>choose(0.2*40,4)*choose(40-0.2*40,4-+4)/choose(40,4)
[1] 0.0007659481
Para dibujar la función de masa de una distribución discreta debemos utilizar la función dbinom. A continuación aparece la correspondiente a una B(10,0.25). Debajo de esta función puede verse el histograma de 1000 valores elegidos al azar de esta misma variable aleatoria. Véase el parecido entre ambos gráficos:
> par(mfrow=c(2,1))
> z<-0:10
> plot(z,dbinom(z,10,0.25),type="h")
> x<-rbinom(1000,10,0.25)
> hist(x)
> par(mfrow=c(1,1))

Variable Aleatoria. Ejemplo y Caracterización
Variable Aleatoria. Ejemplo
Supongamos que se lanzan dos monedas al aire. El espacio muestral, esto es, el conjunto de resultados elementales posibles asociado al experimento, es ,
,
Podemos asignar entonces a cada suceso elemental del experimento el número de caras obtenidas. De este modo se definiría la variable aleatoria X como la función





Caracterización de variables aleatorias.
Tipos de variables aleatorias
Para comprender de una manera más amplia y rigurosa los tipos de variables, es necesario conocer la definición de conjunto discreto. Un conjunto es discreto si está formado por un número finito de elementos, o si sus elementos se pueden enumerar en secuencia de modo que haya un primer elemento, un segundo elemento, un tercer elemento, y así sucesivamente.- Variable aleatoria discreta: una v.a. es discreta si su recorrido es un conjunto discreto. La variable del ejemplo anterior es discreta. Sus probabilidades se recogen en la función de cuantía. (Véanse las distribuciones de variable discreta).
- Variable aleatoria continua: una v.a. es continua si su recorrido no es un conjunto numerable. Intuitivamente esto significa que el conjunto de posibles valores de la variable abarca todo un intervalo de números reales. Por ejemplo, la variable que asigna la estatura a una persona extraída de una determinada población es una variable continua ya que, teóricamente, todo valor entre, pongamos por caso, 0 y 2,50 m, es posible.
Distribución de probabilidad de una variable aleatoria
La distribución de probabilidad de una v.a. X, también llamada función de distribución de X es la función , que asigna a cada evento definido sobre
, que asigna a cada evento definido sobre  una probabilidad dada por la siguiente expresión:
una probabilidad dada por la siguiente expresión:
 y
y 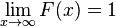
- Es continua por la derecha.
- Es monótona no decreciente.
Función de densidad de una variable aleatoria continua
La función de densidad de probabilidad (FDP) o, simplemente, función de densidad, representada comúnmente como f(x), se utiliza con el propósito de conocer cómo se distribuyen las probabilidades de un suceso o evento, en relación al resultado del suceso.La FDP es la derivada (ordinaria o en el sentido de las distribuciones) de la función de distribución de probabilidad F(x), o de manera inversa, la función de distribución es la integral de la función de densidad:
La función de densidad de una v.a. determina la concentración de probabilidad alrededor de los valores de una variable aleatoria continua.

Variable Aleatoria o Variable estocástica
Variable Aleatoria o Variable Estocástica. (Es una variables estadística)

Una variable aleatoria puede concebirse como un valor numérico que está afectado por el azar. Dada una variable aleatoria no es posible conocer con certeza el valor que tomará esta al ser medida o determinada, aunque sí se conoce que existe una distribución de probabilidad asociada al conjunto de valores posibles. Por ejemplo, en una epidemia de cólera, se sabe que una persona cualquiera puede enfermar o no (suceso), pero no se sabe cuál de los dos sucesos va a ocurrir. Solamente se puede decir que existe una probabilidad de que la persona enferme.
Dado un espacio de probabilidad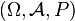 y un espacio medible
y un espacio medible  , una aplicación
, una aplicación es una variable aleatoria si es una aplicación
es una variable aleatoria si es una aplicación  - medible.
- medible.
En la mayoría de los de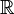 ), quedando pues la definición de esta manera:
), quedando pues la definición de esta manera:
Dado un espacio de probabilidad una variable aleatoria real es cualquier función - medible donde
- medible donde  es la σ-álgebra boreliana.
es la σ-álgebra boreliana.
, es decir, al conjunto de los valores reales que ésta puede tomar, según la aplicación X. Dicho de otro modo, el rango de una v.a. es el recorrido de la función por la que ésta queda definida:...

Una variable aleatoria puede concebirse como un valor numérico que está afectado por el azar. Dada una variable aleatoria no es posible conocer con certeza el valor que tomará esta al ser medida o determinada, aunque sí se conoce que existe una distribución de probabilidad asociada al conjunto de valores posibles. Por ejemplo, en una epidemia de cólera, se sabe que una persona cualquiera puede enfermar o no (suceso), pero no se sabe cuál de los dos sucesos va a ocurrir. Solamente se puede decir que existe una probabilidad de que la persona enferme.
Para trabajar de manera sólida con variables aleatorias en general es necesario considerar un gran número de experimentos aleatorios, para su tratamiento estadístico, cuantificar los resultados de modo que se asigne un número real a cada uno de los resultados posibles del experimento. De este modo se establece una relación funcional entre elementos del espacio muestral asociado al experimento y números reales.
Definición formal
Una variable aleatoria (v.a.) X es una función real definida en el espacio muestral, Ω, asociado a un experimento aleatorio.La definición formal anterior involucra conceptos matemáticos sofisticados procedentes de la teoría de la medida, concretamente la noción de espacio de probabilidad.
Dado un espacio de probabilidad
y un espacio medible , una aplicación es una variable aleatoria si es una aplicación - medible.En la mayoría de los de
), quedando pues la definición de esta manera:Dado un espacio de probabilidad
una variable aleatoria real es cualquier función- medible donde es la σ-álgebra boreliana.Rango de una variable aleatoria
Se llama rango de una variable aleatoria X y lo denotaremos RX, a la imagen o rango de la función, es decir, al conjunto de los valores reales que ésta puede tomar, según la aplicación X. Dicho de otro modo, el rango de una v.a. es el recorrido de la función por la que ésta queda definida:...
Importancia de la estadística en el campo laboral
Importancia de la Estadística en el Campo Laboral

La estadística desempeña un papel de gran utilidad en cualquier ámbito de nuestra vida, sea en el campo educativo, deportivo, empresarial, profesional, financiero, nuevas tecnologías, etc., ya que el objetivo de la aplicación de cualquier técnica estadística, va a estar orientado siempre hacia la mejora del nivel de eficiencia en la toma de decisiones.


|

Suscribirse a:
Entradas (Atom)